Retrieval-augmented generation is a well-understood pattern. Chunk documents, embed chunks into vectors, store vectors in a database, query the database at inference time to retrieve relevant context, inject that context into the LLM prompt. The pattern works well for prose documents — product documentation, legal contracts, news articles. Oracle diagnostic output is not prose documentation. It is something different, and building a RAG pipeline for it required rethinking several standard assumptions.
This article documents the evaluation process that led to selecting Milvus as the vector database for the Oracle AI platform's knowledge store, and explains the chunking strategy we developed specifically for Oracle diagnostic output structure.
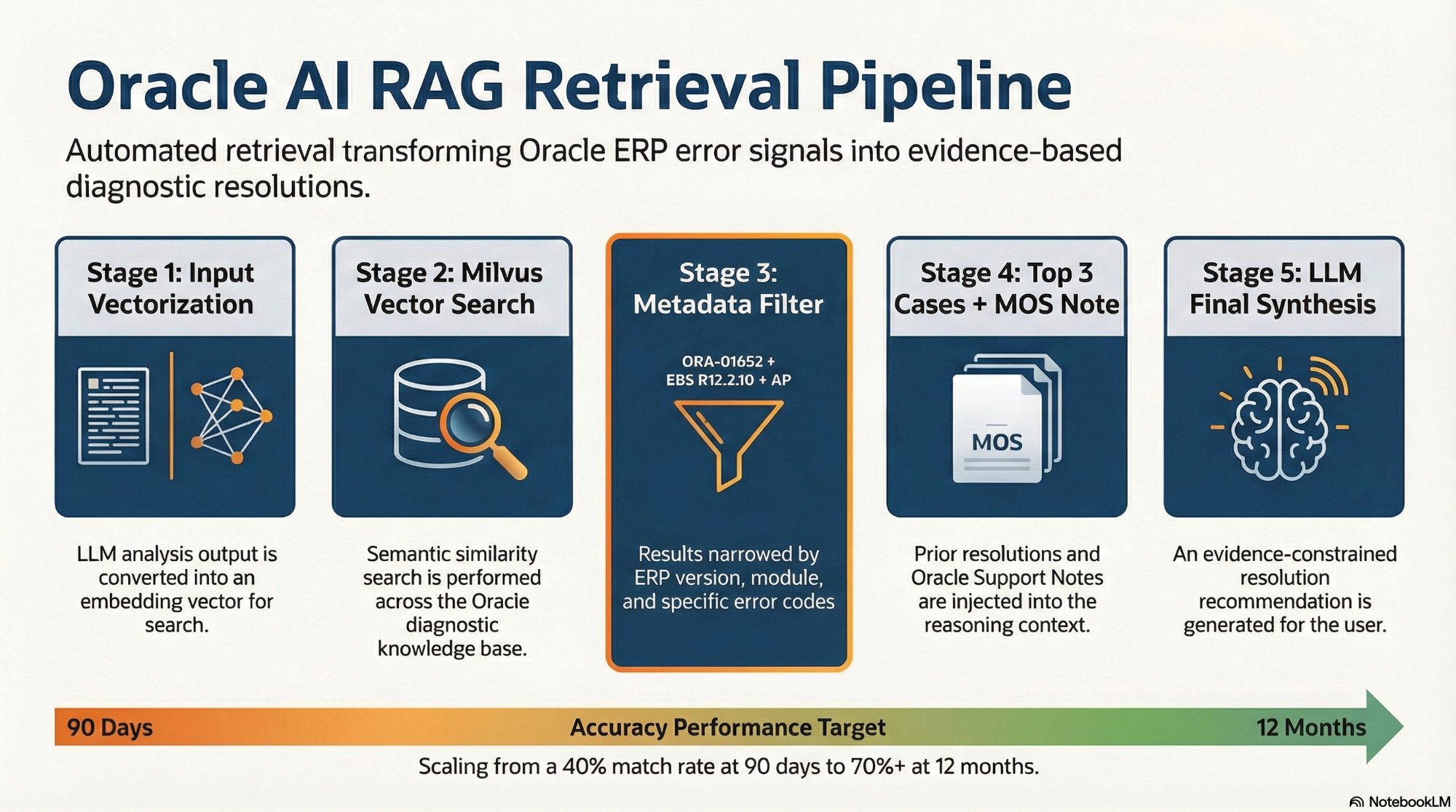
The complete RAG pipeline. The Metadata Filter stage (highlighted) is what makes Oracle-specific retrieval work — generic RAG without version and module filtering returns dangerous cross-version matches.
Why Oracle Diagnostic Output Breaks Standard Chunking
A standard RAG chunking approach splits documents into fixed-size chunks — typically 512 or 1024 tokens — with some overlap between adjacent chunks. This works for prose because prose is semantically continuous: the meaning of one sentence flows into the next, and a 512-token chunk captures a coherent unit of meaning.
Oracle diagnostic output has a completely different structure. Consider a TKPROF trace file. It contains execution statistics organized by SQL statement, with EXEC counts, FETCH counts, DISK reads, BUFFER gets, and ROWS processed for each statement — followed by the full SQL text — followed by the execution plan. The semantically meaningful unit is the complete record for one SQL statement. A 512-token fixed-size chunker will split this record in the middle — separating the execution statistics from the SQL text they describe, or splitting the execution plan from the SQL it belongs to.
When a retrieval query asks "what was the slowest SQL for AP invoice validation?", the chunker needs to return the complete record: statistics, SQL text, and execution plan together. A chunk containing only the statistics — without the SQL text — answers a different question than the one being asked, and the LLM receiving that chunk cannot produce a useful resolution recommendation.
The same problem appears in SQLHC output, concurrent manager diagnostic reports, and AWR data. Every Oracle diagnostic format has an internal structure that fixed-size chunking destroys.
The Hierarchical Chunking Solution
The platform implements a three-level hierarchical chunking model. Level 1 is the full diagnostic session — the complete output of a single diagnostic script run, stored as a parent record. This is too large for LLM context but serves as the authoritative source of truth for audit purposes.
Level 2 splits the diagnostic session at Oracle-specific structural boundaries using regex patterns matched to each diagnostic format. For TKPROF, the splitter recognizes PARSING IN CURSOR markers as section boundaries. For concurrent manager output, it recognizes request ID boundaries. For tablespace diagnostics, it recognizes the tablespace name + metrics block as a natural unit. Each section becomes a child chunk with a reference back to its Level 1 parent.
Level 3 applies recursive semantic splitting within each Level 2 section, producing 300–500 token chunks with 15% overlap. The overlap is non-negotiable for Oracle output — Oracle error messages routinely span two or three lines, and a clean split at a line boundary would separate the error code from its description. The 15% overlap ensures that any two-line Oracle message is fully represented in at least one chunk.
Why Metadata Filtering Was the Deciding Factor
Vector similarity alone is insufficient for Oracle diagnostic retrieval. This is the insight that drove the database selection decision. Consider the problem: the platform stores resolutions for hundreds of Oracle incidents across multiple ERP versions and modules. When a new ORA-01652 incident arrives for an EBS R12.2.10 AP environment, a pure vector similarity search might return the most semantically similar chunk — but that chunk might be a resolution from an EBS R11i environment, or an AR module incident that happened to produce similar diagnostic output patterns.
An EBS R11i resolution is not safely applicable to an R12.2.10 environment. The tablespace management commands, the data structures, and the safe fix paths differ between versions. A retrieval system that returns the R11i resolution because it is semantically similar is actively harmful — it will cause the LLM to recommend a fix path that is wrong for the current environment.
The solution is metadata filtering: every stored chunk carries structured metadata — oracle_error_code, erp_module, erp_version, source_script, resolution_type, environment_id — and every retrieval query filters on this metadata before applying semantic similarity ranking. An ORA-01652 query for EBS R12.2.10 AP only retrieves chunks tagged with that exact error code, ERP version, and module. Semantic similarity operates within that filtered set, not across the entire knowledge base.
The Milvus vs. pgvector Decision
The evaluation came down to two candidates: Milvus and pgvector. Both are self-hostable (a non-negotiable requirement for Oracle environments where data sovereignty matters). Both support metadata filtering. The differences are in scale ceiling and filtering capability.
pgvector is a PostgreSQL extension. Its primary advantage is operational simplicity — it runs in the same Postgres instance used for n8n workflow state, eliminating a separate service deployment. For smaller Oracle environments (under 50 active users, knowledge base expected to stay under 10 million vectors), pgvector is the right choice. The platform supports it as the recommended starting point for new deployments.
Milvus is a purpose-built vector database designed for billion-scale workloads. Its compound metadata filtering capability — the ability to query by error_code == 'ORA-01652' AND erp_version == 'EBS R12.2.10' AND erp_module == 'AP' in a single query — is more powerful than pgvector's filtered search. Above 10 million vectors, Milvus's performance advantage becomes significant. For enterprise Oracle environments with multiple EBS instances, multi-module coverage, and years of accumulated diagnostic history, Milvus is the right long-term choice.
The practical recommendation: start with pgvector. Migrate to Milvus when the knowledge base crosses 10 million vectors or when compound metadata filtering accuracy becomes a material concern. The platform's abstraction layer makes this migration path straightforward — the chunking strategy, embedding model, and retrieval logic are the same for both backends.
What Good RAG Looks Like in Production
In a mature deployment — twelve or more months of accumulated incident resolutions for a stable Oracle environment — the platform achieves context recall rates above 70% for common error codes. This means that for more than seven in ten ORA-01652 incidents, the platform finds a prior resolution from the same environment that is directly applicable to the current incident. The LLM receives both the current diagnostic evidence and a validated historical resolution, producing a fix recommendation that is grounded in what actually worked before.
The compound value of the knowledge base accumulates over time. The first ORA-01652 resolution is produced from scratch using diagnostic scripts and Oracle Support retrieval. The tenth resolution benefits from nine prior cases. The hundredth resolution, for a stable environment, is essentially a lookup — the platform recognizes the pattern immediately and retrieves the validated fix path in seconds. This is the institutional memory that manual Oracle support processes cannot accumulate — because every resolved ticket stays in a ticket system rather than being vectorized, tagged, and made retrievable for the next incident.