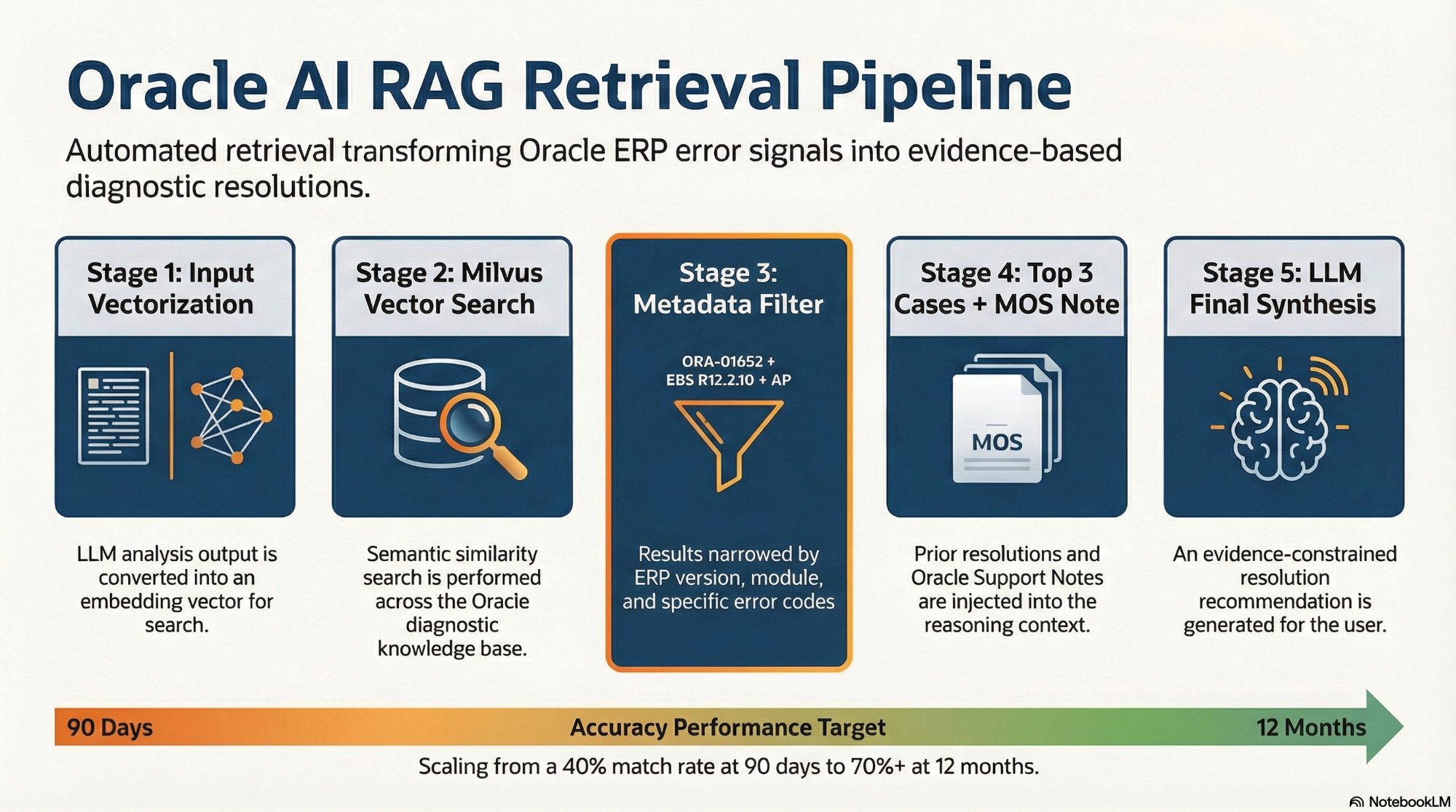
The 5-stage RAG retrieval pipeline. Stage 3 — the Metadata Filter — is what separates Oracle-grade retrieval from generic RAG: it scopes results to the exact ERP version, module, and error code.
The n8n RAG Retrieval Pipeline
The RAG pipeline runs inside n8n as part of the intelligence layer. It activates in Step 4 of every incident resolution — after diagnostic scripts have run and the LLM has produced its initial root cause analysis.
Input Vectorization
n8n converts the root cause analysis output — not the raw diagnostic data, but the structured analysis — into a vector embedding. Using the analyzed output ensures the search query reflects intent rather than raw numbers.
Vector Search with Metadata Filter
n8n queries Milvus using the generated embedding, returning the top N semantically similar chunks. Results are immediately filtered by the current incident's ERP version and module — a result from the wrong version is ranked below a less similar result from the exact matching environment.
collection.search(
data=[query_vector],
anns_field="embedding",
param={"metric_type": "COSINE", "nprobe": 16},
limit=10,
expr="erp_version == 'EBS R12.2.10' and erp_module == 'AP'"
)Top 3 Historical Cases Injected
n8n retrieves the top 3 matching historical cases and assembles them alongside the Oracle Support Notes retrieved by the Playwright agent. The most recent validated internal fix takes precedence over generic documentation in the final LLM context.
Resolution Path Generated
The assembled context is passed to the LLM with a structured prompt constraining output to the evidence presented. The model is explicitly instructed to base its recommendation on the retrieved cases and support notes — preventing hallucinated resolution paths not grounded in validated Oracle fixes.